Subtree of Another Tree
Given the roots of two binary trees root and subRoot, return true if there is a subtree of root with the same structure and node values of subRoot and false otherwise.
Problem Statement
LeetCode-572: Given the roots of two binary trees root and subRoot, return true if there is a subtree of root with the same structure and node values of subRoot and false otherwise.
A subtree of a binary tree tree is a tree that consists of a node in tree and all of this node’s descendants. The tree tree could also be considered as a subtree of itself.
Approach
A simple recursive approach can be used to solve this problem.
- Check if the
rootand thesubRootare identical. If they are, returntrue. - Else, check if the left subtree of the root and the
subRootare identical. If they are, returntrue. - Or, check if the right subtree of the root and the
subRootare identical. If they are, returntrue. - Repeat the above steps for all the nodes in the tree pointed by
root.
But how do we check if two trees are identical? We can do this by checking if the values of the nodes are equal and the left and right subtrees are identical.
Implementation
Here is a java implementation of the above approach:
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
if(null == root || null == subRoot){
return null == root && null == subRoot;
}
return isSame(root, subRoot) ||
isSubtree(root.left, subRoot) ||
isSubtree(root.right, subRoot);
}
private boolean isSame(TreeNode root, TreeNode subRoot){
if(null == root || null == subRoot){
return null == root && null == subRoot;
}
return root.val == subRoot.val &&
isSame(root.left, subRoot.left) &&
isSame(root.right, subRoot.right);
}
Complexity Analysis
The time complexity of the above approach is $O(n*m)$ where $n$ is the number of nodes in the root tree and $m$ is the number of nodes in the subRoot tree. This is because for each node in the root tree, we are checking if the subRoot tree is a subtree of the root tree.
The space complexity of the above approach is $O(n + m)$ as at most $n + m$ elements are stored in the call stack during the recursive calls.
Follow-up
We can optimize the above approach by using a string representation of the tree and checking if the subRoot tree is a substring of the root tree.
Note that the string representation of the tree should be unique. The usual pre-order or post-order traversal of the tree may not be unique.
Consider the following two examples:
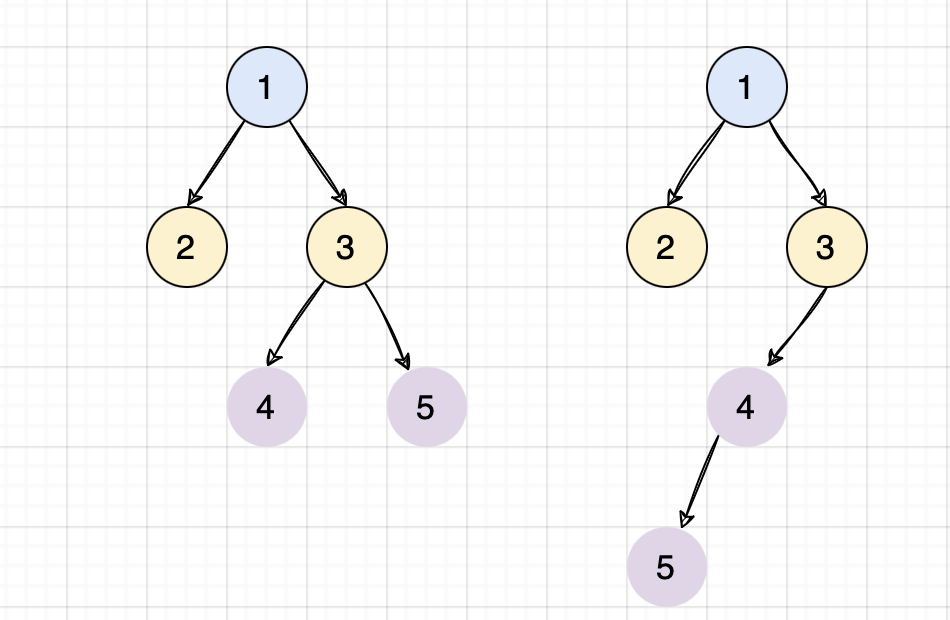
Pre Order Traversal
The pre-order traversal of the above two trees is the same [1, 2, 3, 4, 5]. But the trees are different. Same is the case with in-order and post-order traversals.
This does not work as the trees can have the same traversal but different structures. While traversing the tree, we are loosing the information about the structure of the tree. But if we add a special character to the traversal denoting the absence of a child node, we can retain the structural information as well.
Anytime we see a null node, we can add a special character to the traversal. This way, the traversal will be unique.
This approach has a time complexity of $O(n + m)$ and a space complexity of $O(n + m)$.
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
String rootString = build(root);
String subString = build(subRoot);
return rootString.contains(subString);
}
private String build(TreeNode root){
if(null == root){
return null;
}
return "#" + root.val + build(root.left) + build(root.right);
}